
Training Diffusion Models with Reinforcement Learning

Written by: Kevin Black
Diffusion models have recently emerged as the de facto standard for generating complex, high-dimensional outputs. They are known for producing stunning AI art and hyper-realistic synthetic images, but have also been applied in drug design and continuous control. The core principle of diffusion models involves the iterative transformation of random noise into a sample, often guided by a maximum likelihood estimation approach.
However, many use cases aim not merely to replicate training data, but to achieve specific objectives. In this post, we discuss how reinforcement learning (RL) can train diffusion models to meet these unique goals. Specifically, we finetune Stable Diffusion for various objectives, incorporating feedback from a large vision-language model to enhance the model’s output quality. This demonstrates the potential for powerful AI models to enhance one another without human intervention.
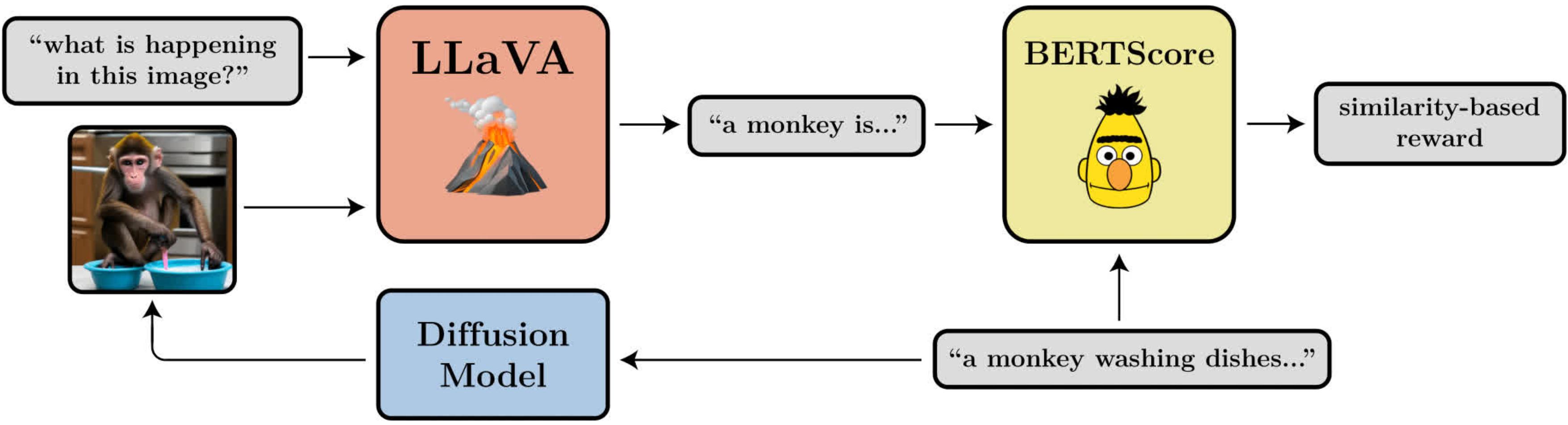 A diagram illustrating the prompt-image alignment objective using LLaVA, a large vision-language model.
A diagram illustrating the prompt-image alignment objective using LLaVA, a large vision-language model.
Denoising Diffusion Policy Optimization
In adapting diffusion to RL, we make a fundamental assumption: for a given sample (e.g. an image), a reward function can evaluate its quality. The goal is for the diffusion model to maximize this reward function. Traditional diffusion models lean on maximum likelihood estimation (MLE) to generate samples, but in the RL context, we use the reward-weighted regression (RWR) method, inspired by existing RL algorithms.
However, this method presents challenges. Our denoising diffusion policy optimization (DDPO) algorithm overcomes these by considering the entire denoising sequence. By viewing the diffusion process as a Markov decision process (MDP), we leverage advanced RL algorithms that focus on multi-step MDPs, using exact likelihood calculations for each denoising step.
We’ve applied policy gradient algorithms due to their past success in language model finetuning. This led to two DDPO variants: DDPO<sub>SF</sub> (using the REINFORCE policy gradient) and DDPO<sub>IS</sub> (following the proximal policy optimization (PPO) method).
Finetuning Stable Diffusion Using DDPO
We finetuned Stable Diffusion v1-4 using DDPO<sub>IS</sub> for the following reward functions:
- Compressibility: Ease of image compression using JPEG.
- Incompressibility: Difficulty of image compression using JPEG.
- Aesthetic Quality: Evaluated by the LAION aesthetic predictor.
- Prompt-Image Alignment: Uses LLaVA to describe the image, then matches this description to the prompt using BERTScore.
For finetuning, we provided prompts like “a(n) [animal]” for the first three tasks. For prompt-image alignment, we gave prompts like “a(n) [animal] [activity]”.

We also explored DDPO’s application in prompt-image alignment, observing a trend toward a more cartoonish style.

There is a lot more they covered on their website!