It’s not always easy to distinguish between existentialism and a bad mood.
- 4 Posts
- 329 Comments

 8·1 day ago
8·1 day agoYes exactly how can you write an entire thing treating rationalism like something you can do an apostasy out of and never mention Yud once.
I assume the personal perspective is him tacitly admitting to being attracted to skepticism for the debate bro culture, especially the parts that bordered on harassment. Even the inciting incident of “leaving rationalism” is framed more as him growing out of the need to long-form debate someone, specifically James Damore, the google engineer who published a manifesto about how women don’t belong in tech.
I don’t know the author so I don’t know if it is important that he was fine with pranking the timecube guy but decided enough is enough when it was time to take a pro-feminist side.
The Guardian published a William McAskill editorial in the what-if-the-stateless-text-generators-had-moral-agency genre of fiction, and Emily Bender did a thread
From the article:
But the sheer pace of growth in AI means that, once we produce the first artificial moral patients, we will soon after have enormous quantities of them. After a few years, so many morally significant AI systems could exist that their collective interests would outweigh those of all humans on Earth combined.
Get fucked, Will.
But also, if we grant the untenable sci-fi premise, this would be like a star trek episode where the federation cedes unconditionally to the expansionist alien fascists of the week if they have a much greater population because that’s all it takes to outweigh the other side’s moral concerns.
Earth-Trisolaris Organisation-ass moral framework.
The Leverage article kept referring to him as “the slovenian” and that’s at least honorary eastern europe, but I’ve no idea if he actually grew up there.
If the argument is that too much rationaltruism fried his brain then fine I guess.
Otherwise I don’t think United Healthcare doing AI assisted fraud falls into any rationalist framework of doom, and also those people are allergic to direct action.
Also the article is already setting the bar very high by using the Zizians, a sect that’s almost completely predicated on semi-obsure rationalist lore, as their first point of reference for rationalism gone wild.
Sounds like he went for the low hanging fruit to showcase his business and ate shit, good to know.
His great founder theory certainly seems amenable to going all in on dictators.
Attempting to credit Luigi’s actions to AI millenarianism putting him in a weird headspace almost feels like stolen valor.
Still, if that’s where his mental health defence is going to hinge on then I guess it’s relevant.
[Tim Urban] goes on to claim that ASI, with an IQ of 12,000, will eventually replace humankind as the dominant species on the planet:
That IQ works like mana points is both a widespread misconception and a red flag that you’re far more ignorant than you let on.
Yeah, the foam-at-the-mouth racist college drop out with an imaginary phd in race science and at least one nazi alt that we know of is his overall top account to boost by some margin.
I don’t think I’ve heard of Nicholas Decker.
Was it really the sensible position that the poorest country in Europe would go on to embarrass an ostensible superpower? Predicting a Russian victory in the short term in the early days doesn’t seem too daring a hot take.
It was mostly the analysts who were predicting a three day walk in the park with the ukrainians cheering them on as liberators that turned out problematic all the way.
These are agents, meaning software that perceives, decides, and acts on its own, a category well past the chatbot.
Are these agents in the room with us now?
How can all this possibly be enforceable.
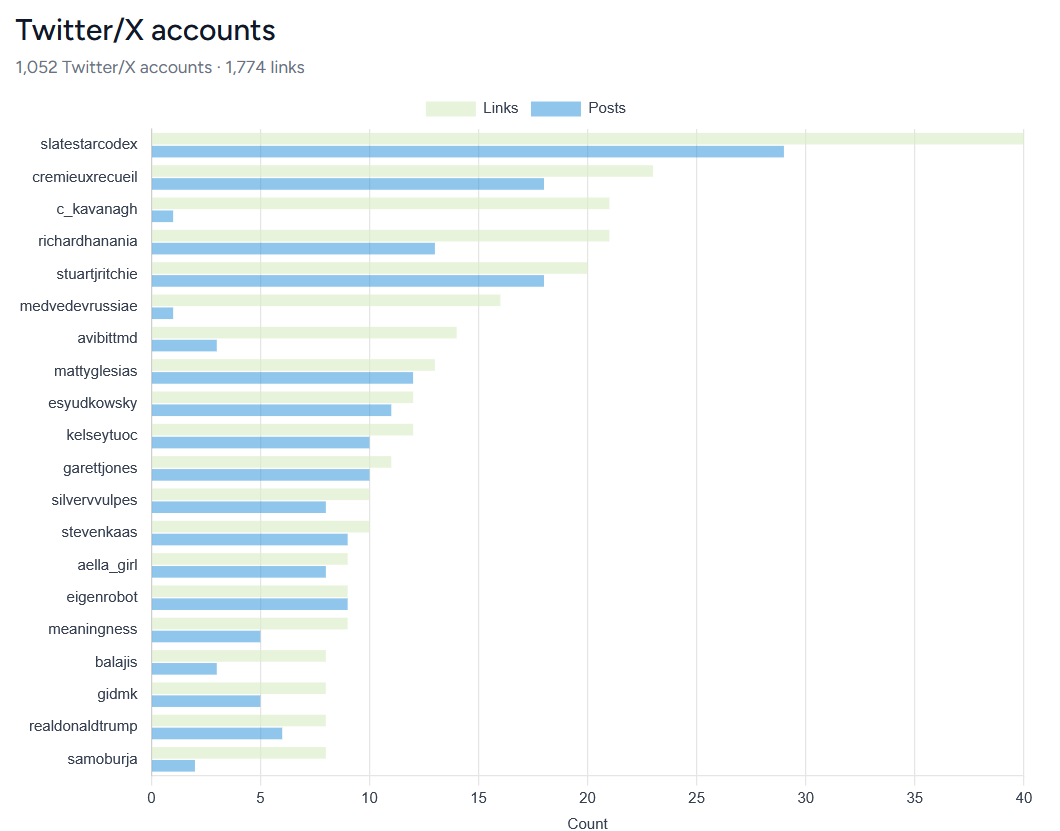
So this exists: https://readscottalexander.com/stats/links
Link Stats
Across every post, these are the external websites Scott Alexander links to most often. “Links” counts every hyperlink; “Posts” counts how many distinct articles link there.
So far these are probably the clearest non-leaked emails indication of what the good doctor actually believes.
That’s a non-provably non-punchable face if I’ve ever seen one.
Also he seems to be the opposite of charismatic.
Yeah, I guess I’m splitting hairs, cult leader is a very open ended job description after all.
Scott is hilariously uninformed
Elsewhere he is comparing their orwelian chipset distribution control scheme to health inspectors making sure supermarkets don’t sell spoiled milk. He just says whatever as long as he thinks it’ll help convince more people than it drives away, and his fanbase goes along with it because they think that’s how he gets to be the normie whisperer.
This makes me feel there really is no telling what actual agenda the rationaltruists’ would enact if they ever get to dictate policy.
Siskind just posted a follow up to his coverage of ai2040, apparently he’s having a bit of a hard time selling his crowd on the really obvious totalitarian implications of instituting a global surveillance system to track and remotely disable chipsets to make sure rogue elements can’t secretly conjure the robot god prematurely.
It’s important too, chip registration is a big part of the ??? item in the to-do list, right before “China and US passionately french kiss, agree to pause AI research”
Enjoyed the writeup, thanks for gazing into the abyss!
This is a classic rationalist fallacy that we see repeated throughout the piece of assuming that ultimately if you express the argument properly everyone will agree on the right thing
This is complementary to their heterodoxy fetish, leading to fringe or outright bonkers but excruciatingly formalistic positions routinely sleight-of-handing themselves into prominence in the movement.
It’s fine for AIs to get better at using valid arguments and evidence to convince people of things for the right reasons. That kind of persuasion is asymmetric: it works much better when the argument pushes towards the truth.
That’s not how the postmodern condition works
That’s just rationalists believing that once you amass enough IQ/Mana points you unlock the mind control spell. Basically if you aren’t buying what the great-men-of-history-du-jour are selling the AIs will cast domination on you for the greater good.
Eliezer Yudkowsky - who totally isn’t a cult leader
He is definitely a cult enabler and a huge cult beneficiary, but I don’t think I’ve ever seen evidence he could lead shit to fuck.
Diversity and inclusion is suddenly great if it involves fascists doing entryism.
If your property is outside the solar system, you will need to either go into cryosleep or upload yourself to a computer to survive the journey.
Reminder that rationalists have developed a completely mysticalised conception of brain uploading that’s very functionally similar with old timey souls, mostly so they don’t need to deal with the SOMA problem of every instance of uploaded consciousness being a completely separate self-actualised entity.
Like how exactly is a digital impression of my personality being shipped to alpha centauri to inspect my holdings affect my personal experience? How is it supposed to be interchangeable with using some other made up technology that takes me there in person?
See, it works like this, no one knows what consciousness is, but it’s probably a mathematical object, and if your current conscious self is the same as the conscious self that will be inhabiting your body next friday, and also if a supreme being wants to torture you after you are dead…


If you don’t mind reading comics online you could check Fairmeadow.